Webサイト上の表の特定の列データだけ取得する方法のあれこれ
下記URLはWindows10に標準でインストールされているフォントの一覧なんですが、このような表で枠で囲んだ特定の列データのテキスト情報だけ取得したい場合ってありますよね。
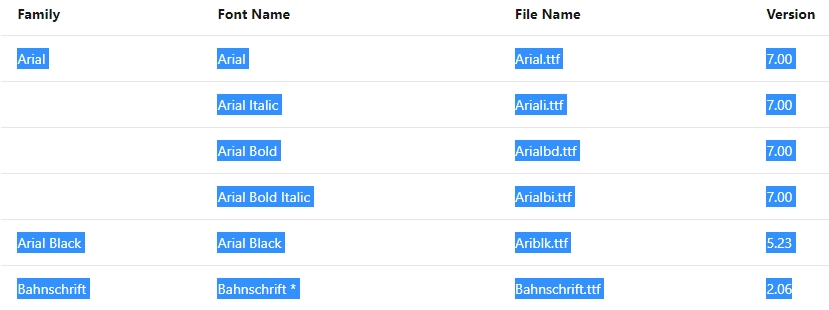
普通に選択すると下図のようになるのでちょっと工夫が必要になります。
Microsoft Expression Web 4 でのやり方
今までは、Microsoft Expression Web 4(MEW4)でやっていたのでまずはその方法を紹介します。尚、MEW4は公式にはもう配布されていませんがWeyback Machine経由でダウンロードできるサイトはあります。
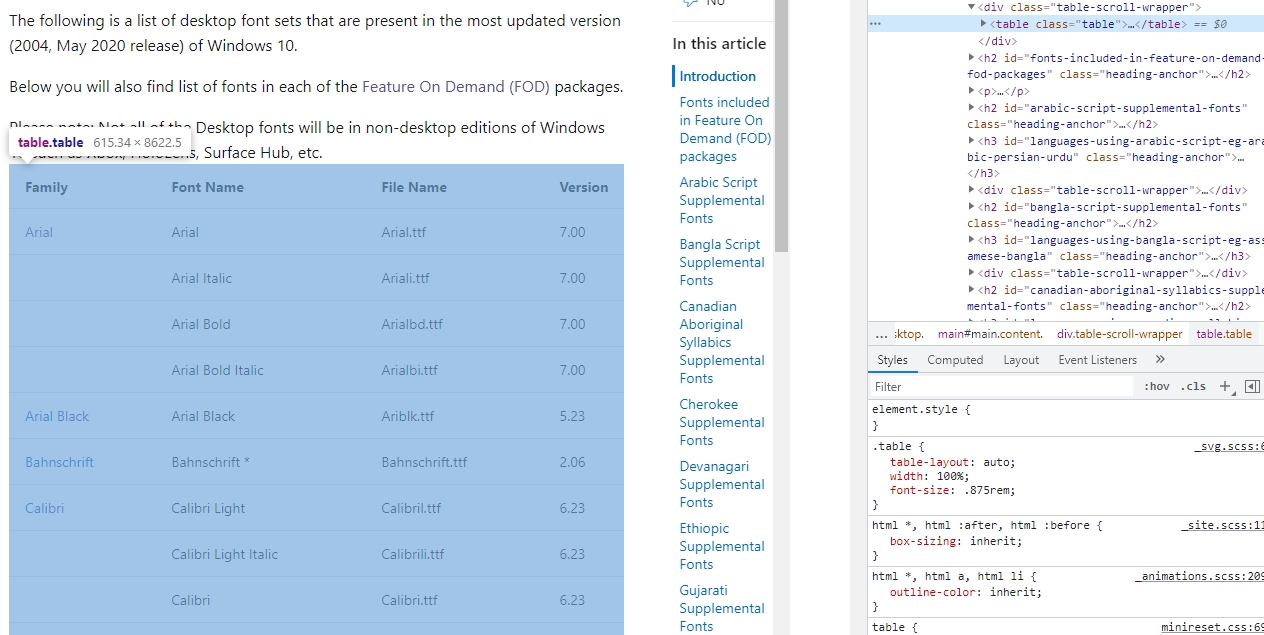
ディベロッパーツール(Ctrl + Shif + I、若しくは右メニューの「検証」で開く)を開きます。次に「Ctrl + Shift + C」でTableタグを選択した状態で右メニューを開き、「Copy」→「Copy outerHTML」でコピーします。
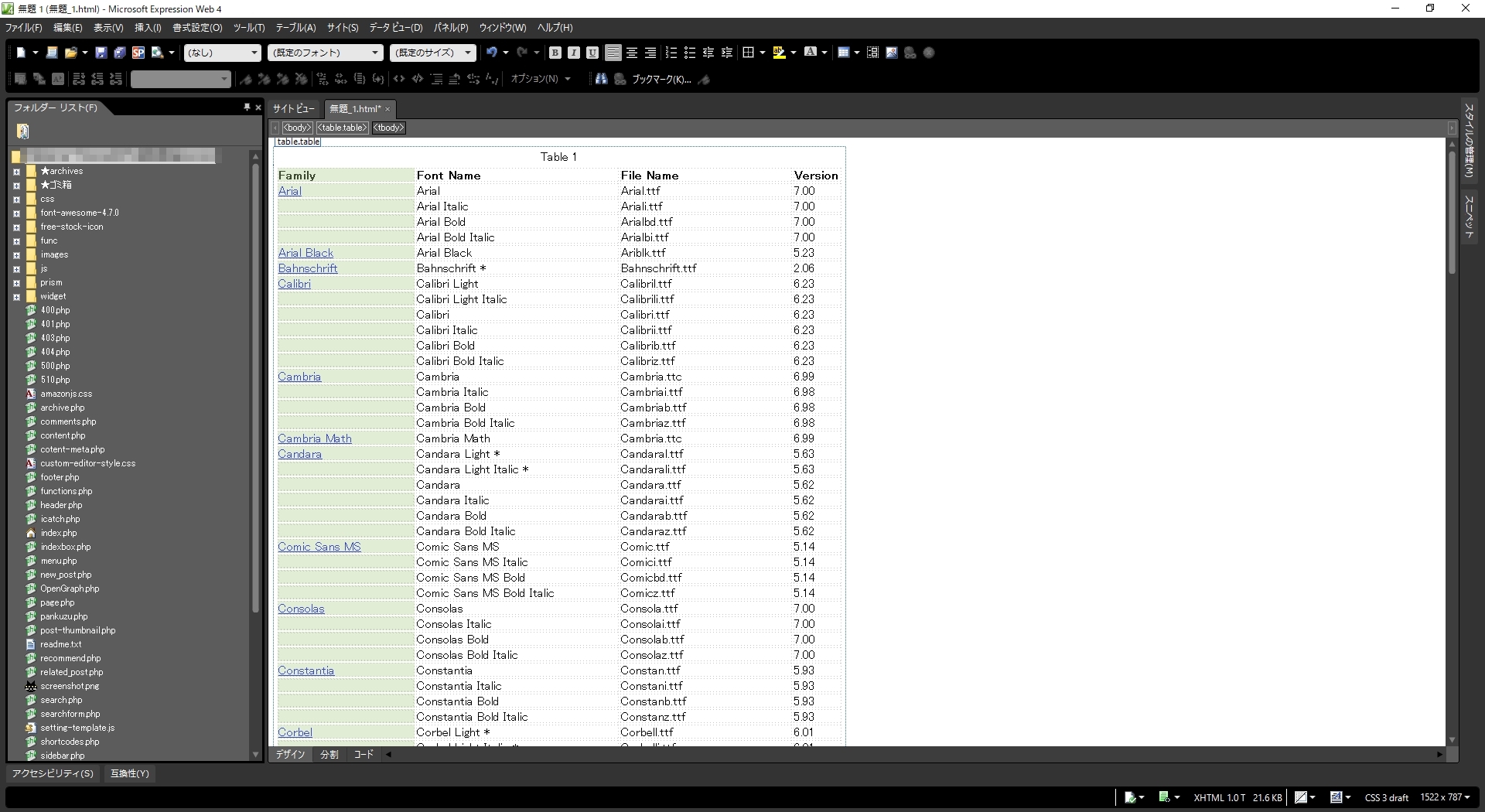
Microsoft Expression Web 4でHTMLページに張り付けてデザインビューで見ると列単位で選択できるようになるのでこのデータをコピペして利用していました。
IMPORTHTML関数を使った方法
GoogleスプレッドシートのIMPORTHTML関数を使うと列のデータを選択できるようになります。尚、この関数はエクセルでは使えないようです。
Googleスプレッドシートで新規ファイルを作成し、A1セルを選択して下記の関数を記載すると記載したURLにある一番最初のTableタグのデータを取得することができます。
=IMPORTHTML("https://docs.microsoft.com/en-us/typography/fonts/windows_10_font_list","table",1)
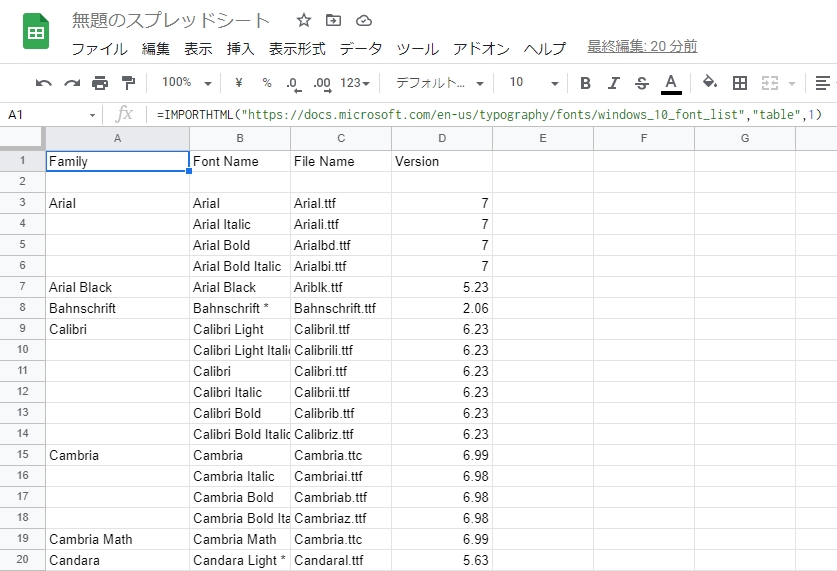
このようなれば後は自由に列や行を選択できるので好きな範囲のデータを取得できます。
IMPORTHTML関数の構文です。
構文
=IMPORTHTML(URL,クエリ,指数)
例
=IMPORTHTML("url","table",1)
- URL – 検証するページの URL でプロトコル(http:// など)も含めて記載し、ダブルクォーテーションで囲みます。
- クエリ – “list”(リスト) か “table”(表)を指定します。
- 指数 – 対象の表またはリストについて、HTML ソース内で表示されている順番を指定(※Tableタグが一つしかない場合は「1」と記載)します。
標準でインストールされる日本語フォントはJapanese Supplemental Fonts(日本語補足フォント)もあるようです。
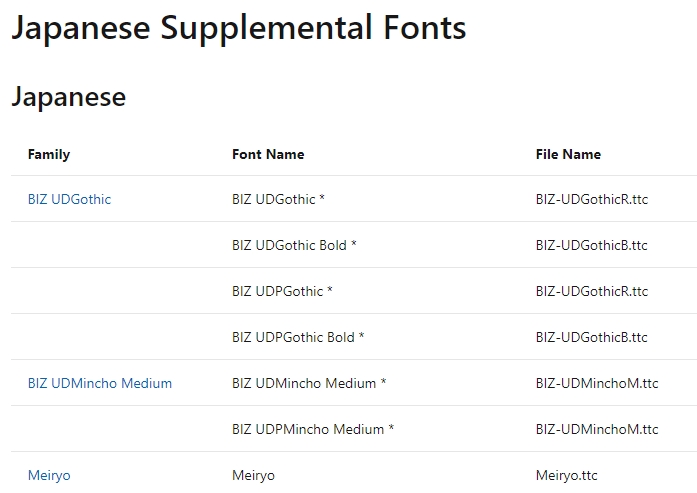
そちらは13個目のTableタグなので下図のように記載します。尚、最後にデータを値として抜き出す場合は同じ列に記載しても構いません。
日本語の補足フォント
=IMPORTHTML("https://docs.microsoft.com/en-us/typography/fonts/windows_10_font_list","table",13)
列を選択して必要なデータをコピーし、新しいシートに「特殊貼り付け」→「値のみ貼り付け」で張り付けます。

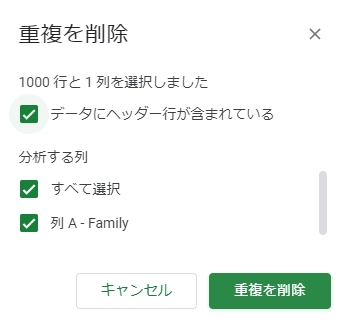
下図のように空白行がある場合は「データ」→「重複を削除」から削除できます。


関数がない値だけの表なので好きなようにデータを操作することができます。

実際にインストールされたフォント一覧は下記URLに記載しています。



「 ネット 」カテゴリー記事一覧

FODを使ってみた感想
下記URLはWindows10に標準でインストールされているフォントの一覧なんですが、このような表で枠で囲んだ特定の列データのテキスト情報だけ取得したい場合って…
2025/10/24
「NHK ONE」へ移行手続きをする
下記URLはWindows10に標準でインストールされているフォントの一覧なんですが、このような表で枠で囲んだ特定の列データのテキスト情報だけ取得したい場合って…
2025/10/08
U-NEXT 青い再生バーを削除したい ~再生履歴のリセット!
下記URLはWindows10に標準でインストールされているフォントの一覧なんですが、このような表で枠で囲んだ特定の列データのテキスト情報だけ取得したい場合って…
2025/09/05
PayPal(ペイパル)「追加情報をご提供いただく必要があります」に対処
下記URLはWindows10に標準でインストールされているフォントの一覧なんですが、このような表で枠で囲んだ特定の列データのテキスト情報だけ取得したい場合って…
2025/07/05グーグルから「重大なセキュリティ通知」が来る! パスワード漏洩?
下記URLはWindows10に標準でインストールされているフォントの一覧なんですが、このような表で枠で囲んだ特定の列データのテキスト情報だけ取得したい場合って…
2024/09/02「カ)エイシス」という会社から謎の入金が…?!
下記URLはWindows10に標準でインストールされているフォントの一覧なんですが、このような表で枠で囲んだ特定の列データのテキスト情報だけ取得したい場合って…
2023/06/23